curl https://www.sqlite.org/snapshot/sqlite-snapshot-202002271621.tar.gz | tar -xzv
cd ./sqlite-snapshot-202002271621 &&
./configure --disable-fts4 --disable-fts5 --disable-json1 --disable-rtree
make && strip -d ./.libs/libsqlite3.a ./.libs/libsqlite3.so.0.8.6
ls -hs ./.libs/
1.1M libsqlite3.a
868K libsqlite3.so.0.8.6IOWOW
Motivation and history
What we are looking for?
Requirements summary
Trying avoid reinvention of a wheel
Trying avoid reinvention of a wheel
Anything else?
Out of review
IOWOW architecture
Why we have developed IOWOW persistence layer based on Skiplist data structure?
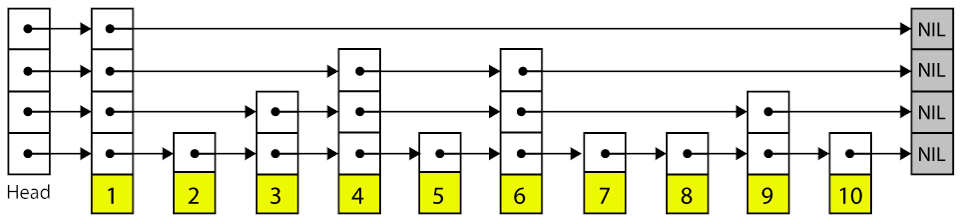
Skiplist drawbacks
Benchmarks
Benchmarks
Benchmarks environment
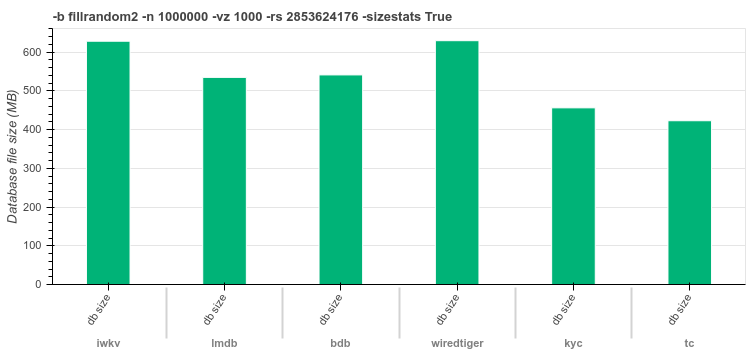
Storage efficiency
Insert 1M records
16byte keysRandom values of
[0, 1000]bytes length
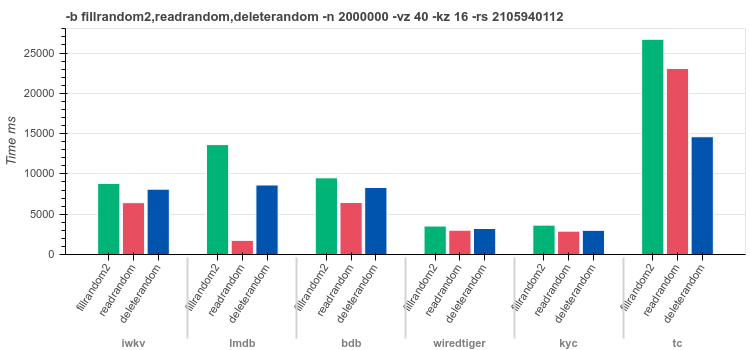
16byte keysRandom values of
[0..40]bytes lengthfilrandom2 - insert
2Mrandom distributed recordsreadrandom - read
2Mrecords in random orderdeleterandom - delete
2Mrandom keys
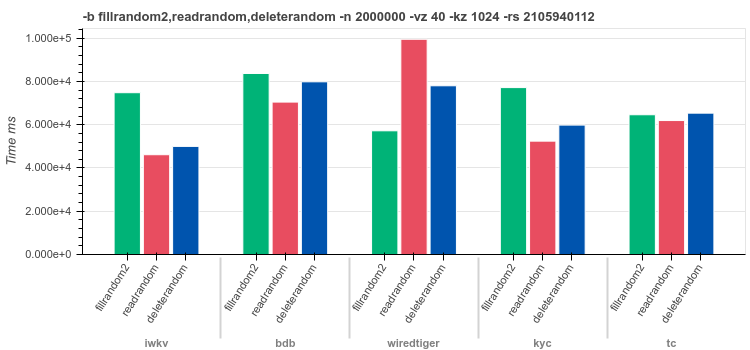
1024byte keysRandom values of
[0..40]bytes lengthfilrandom2 - insert
2Mrandom distributed recordsreadrandom - read
2Mrecords in random orderdeleterandom - delete
2Mrandom keys
LMDB is out of scope since keys greater than 511 bytes are not supported by default
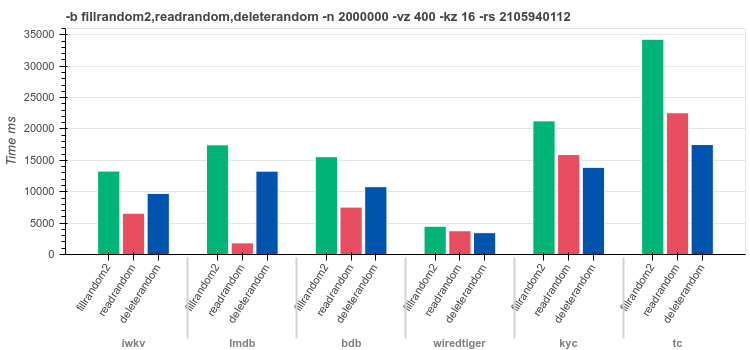
16byte keysRandom values of
[0..400]bytes lengthfilrandom2 - insert
2Mrandom distributed recordsreadrandom - read
2Mrecords in random orderdeleterandom - delete
2Mrandom keys
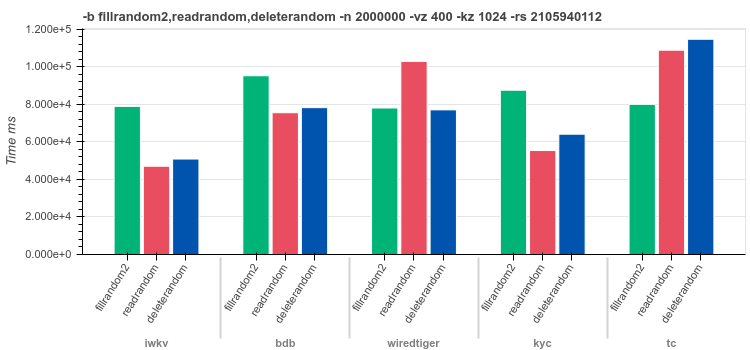
1024byte keysRandom values of
[0..400]bytes lengthfilrandom2 - insert
2Mrandom distributed recordsreadrandom - read
2Mrecords in random orderdeleterandom - delete
2Mrandom keys
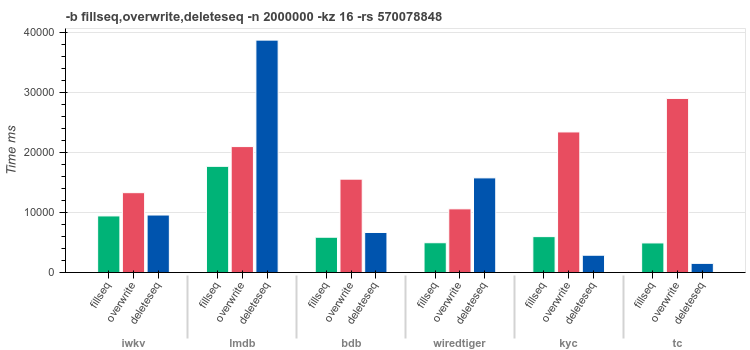
16byte keys400byte valuesfilseq - insert
2Mrecords in ascending orderoverwrite - overwrite
2Mvalues for random keysdeleterandom - delete
2Mrandom keys
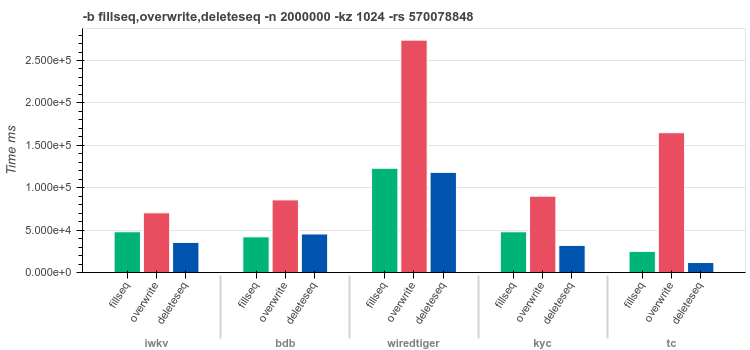
1024byte keys400byte valuesfilseq - insert
2Mrecords in ascending orderoverwrite - overwrite
2Mvalues for random keysdeleterandom - delete
2Mrandom keys
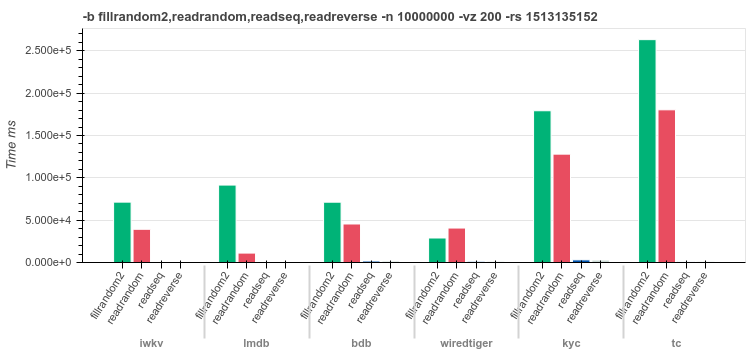
16byte keysRandom values of
[0..400]bytes lengthfilrandom2 - insert
10Mrandom distributed recordsreadrandom - read
10Mrecords in random orderreadseq - read
10Mrecords sequentiallyreadreverse - read
10Mrecords sequentially in reverse order
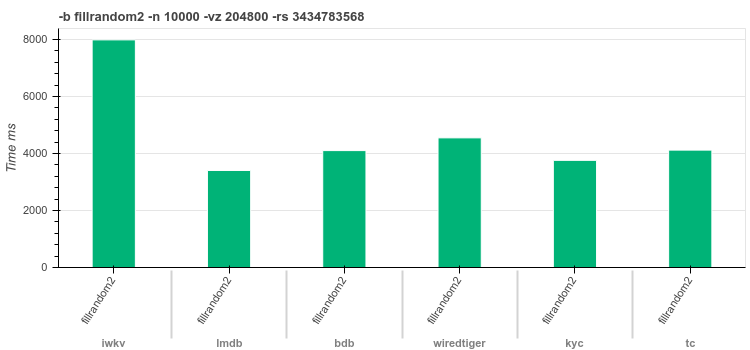
16byte keys200Kbvaluesfilrandom2 - insert
10Krandom distributed records
IOArena benchmarks
IOArena benchmarks
Very good throughput performance (270 Kops/s) especially for small keys: iowow faster than rocksdb, wirediger and lmdb
# Fill db with 4M keys then query it
./ioarena -n 4000000 -k 8 -v 16 -B set,get -D iowowiowow vs rocksdb:
